Linux内核数据结构-list
1.前言
最近的项目中需要自己实现一个list,顺便研究了下linux内核的list实现(代码在此),记录在本篇文章中,供您参考。
本文仅展示部分代码片段,完整的代码已经上传至我的github仓库。
我们会从一个简单的例子入手,串联相关的知识。
2.初始化list
我们假设要存放一个任务列表,每个任务有一个task_id属性来标识这个任务。然后我们需要先定义这样一个链表的节点元素类型:
struct task_node_t
{
int task_id;
struct list_head list_node;
};我们注意到这里面有一个struct list_head,这个结构体是linux内核链表自带的结构体,代表linux链表的节点元素,定义如下:
// copy from kernel/include/linux/types.h
struct list_head {
struct list_head *next, *prev;
};如上所示,它定义了链表的next和prev元素,类型是指针,指向的对象类型是它自己。
这就引出了linux内核链表的第一个关键设计:把链表节点嵌入用户自定义类型中(而不是反之)。
使用这个关键设计的目的是实现泛型,这一点在后面的篇幅中我们会详细说,这里先卖个关子。
定义了链表节点之后,我们需要对其进行初始化,可以使用下面的代码:
//init list head
LIST_HEAD(task_list_head);LIST_HEAD是linux内核链表自带的宏,定义如下:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)这里其实是定义了一个task_list_head变量,类型是struct list_head,然后给他的next和prev变量赋值,指向他自己,即:
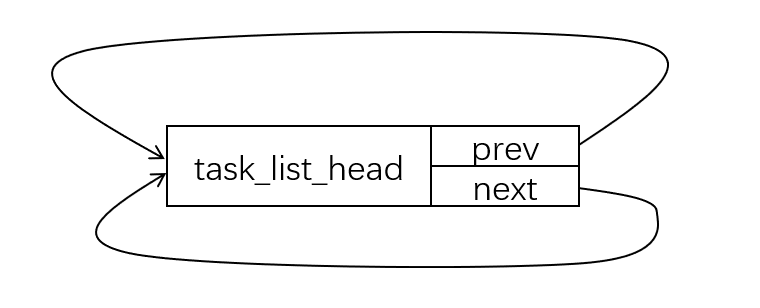
3.添加元素
我们给list增加100个元素:
//insert 100 elements(from head)
for(i=0; i<100; ++i)
{
struct task_node_t *p_task = (struct task_node_t *)malloc(sizeof(p_task));
p_task->task_id = i;
INIT_LIST_HEAD(&p_task->list_node);
list_add(&p_task->list_node, &task_list_head);
}我们新建了100个元素,为其id赋值,然后调用INIT_LIST_HEAD初始化结构体的list节点字段。
INIT_LIST_HEAD其实是一个小函数,而非宏定义。它是linux内核链表自带的,定义如下:
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}可以看到,我们调用该函数的时候,是把该list节点的next和prev都指向了自己(跟上面初始化头节点的操作一样)。
然后我们调用了list_add函数,实现如下:
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}这里其实是把新节点插在了头节点之后,原有元素之前(即从头部插入)。插入效果如下:
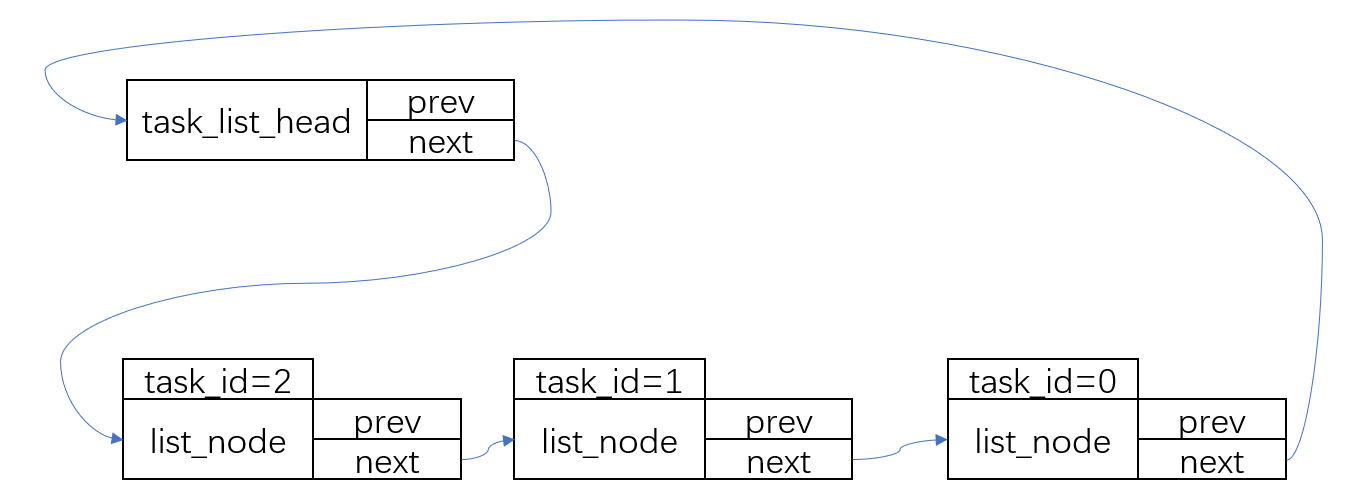
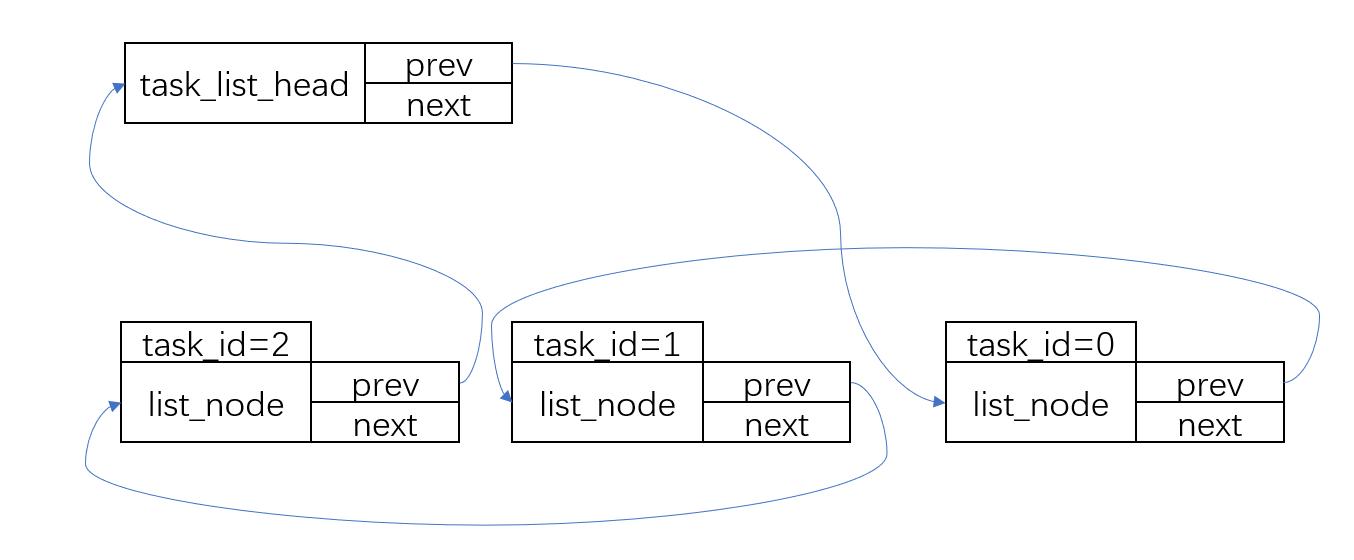
不知道你注意到了没有,这是个双向链表。
除了list_add外,还有一个list_add_tail函数,定义如下:
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}实现极其简洁,就是把__list_add的参数换了一下,与list_add接口不同,tail版本在追加元素时是从尾部追加的。
4.遍历list
4.1 测试代码
先看遍历代码:
struct task_node_t *p_task;
//foreach and print
list_for_each_entry(p_task, &task_list_head, list_node)
{
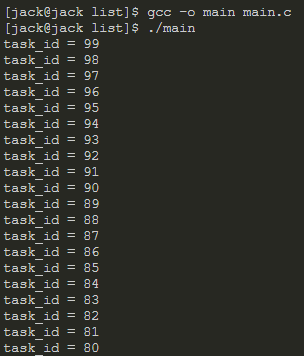
printf("task_id = %d\n", p_task->task_id);
}p_task是遍历列表时用的临时变量,task_list_head是链表头,list_node是要遍历的元素结构体中,充当链表节点的那个字段的名称,以我们的struct task_node_t为例,是list_node。
4.2 list_for_each_entry
list_for_each_entry是个宏定义,代码如下:
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
#define list_entry_is_head(pos, head, member) \
(&pos->member == (head))
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = list_next_entry(pos, member))信息量比较大,我们一点一点分析。
list_for_each_entry其实是一个for循环,需要特别注意的是,它的终结条件是,便利到头节点的时候停止。这一点其实也比较好理解,因为linux内核链表是个双向链表,遍历了一圈回到头部的时候就证明遍历完了。
4.3 container_of与offsetof
我们继续看list_first_entry,它调用了list_entry,list_entry又调用了container_of,而container_of是个宏,代码如下:
// copy from kernel/include/linux/kernel.h
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
((type *)(__mptr - offsetof(type, member))); })这是一个很著名的宏,作用是根据结构体的某个成员变量的地址,求结构体的地址。
以我们的struct list_head list_node为例,我们其实是想根据list_node的地址,求包含它的struct task_node_t的地址。
其实算起来比较简单,我们只需要知道list_node在包含它的task_node_t结构体中的偏移量,然后用list_node的地址减去这个偏移量即可。
这个偏移量可以通过offsetof宏求出,这个宏是标准宏,包含stddef.h即可使用,定义如下:
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)原理也比较简单,当元素结构体的地址是0时,它的成员的地址值就是偏移量!
4.4 list_first_entry等
我们继续回头看list_first_entry,它先调用了list_entry,作用是将list_node的指针翻译成包含它的struct task_node_t的指针。
list_first_entry的ptr参数其实是我们定义的头结点(task_list_head)的指针,ptr的next指向的是第一个struct task_node_t元素的list_node的成员变量,我们求他的container,其实求得的就是第一个struct task_node_t元素的指针(存放在p_task变量中)。
理解了list_first_entry,另外两个也就不难理解了。
list_next_entry底层也是调用的list_entry,只不过他传入的是自己下一个节点的list_node变量的指针,求出来的自然是下一个元素。
需要特别注意的是,当遍历完链表的最后一个元素时,它会指向头结点。我们的头结点task_list_head是没有外围的结构体包裹的,因此这时返回的指针其实并不指向一个真正的struct task_node_t结构体(严格来讲,这是个非法的地址)。
理解了上面一点,我们再来看list_entry_is_head的实现。链表的头结点没有外围包裹它的结构体,因此上述“非法”的struct task_node_t结构体指针的list_node成员变量,其实指向的就是他自己。
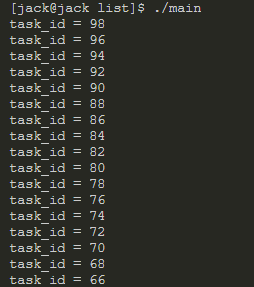
说了这么多,我们看下运行效果:
5.删除元素
5.1 list_del
删除元素的接口是list_del,实现代码如下:
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = NULL;
entry->prev = NULL;
}看起来很简单,就是把他前面的元素的next指向后面的元素,后面元素的prev元素指向前面的元素,然后把他自己的prev和next指针置空。
5.2 遍历时删除
下一个问题是如何在遍历时删除。用过stl的都知道,stl的list在删除元素的时候回遇到迭代器失效的问题,linux内核的list同样无法避免。
为此,linux内核提供了一个专用的safe遍历接口:
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member), \
n = list_next_entry(pos, member); \
!list_entry_is_head(pos, head, member); \
pos = n, n = list_next_entry(n, member))其原理是利用一个临时的变量n保存当前元素的下一个元素,一轮遍历结束时,把遍历变量pos赋值为n,然后再求下一个元素。
测试代码如下:
struct task_node_t *p_task;
struct task_node_t *p_task_tmp;
//delete odd elements
list_for_each_entry_safe(p_task, p_task_tmp, &task_list_head, list_node)
{
if(p_task->task_id % 2 == 1)
{
list_del(&p_task->list_node);
free(p_task);
}
}运行效果如下:
6.总结
看完linux内核的list实现,不由得感慨,果然你大爷还是你大爷。
短短百余行代码就实现了一个支持泛型的list,函数的封装很考究,可读性很好,但是没有一句废话;编程技巧的运用也恰到好处,平衡了效率、简洁和可读性。
这样的代码,没个10年的功力,绝对写不出来。
人外有人天外有天,努力吧骚年。